随着大模型技术从数字世界的文本生成溢出到物理世界的实体交互,具身智能(Embodied AI)已然成为人工智能领域的下一个必争之地,但这同时也为算法面试划定了一道全新的分水岭。对于求职者而言,单纯掌握 Transformer 架构或传统的机器人运动学已不足以应对当前的考核标准;面试官的核心关注点已从单一模态的算法优化,转向了对多模态大模型与物理实体深度融合的系统性考察。要在这一新兴赛道中确立竞争优势,你必须建立起跨越软件与硬件的复合知识体系:不仅要透彻理解从“LLM as Planner”的模块化分层架构向 RT-2 等端到端 VLA(Vision-Language-Action)模型演进的技术必然性,更要深谙 Sim-to-Real(仿真到现实)迁移中的数据鸿沟解决方案,以及如何在边缘侧解决高频控制与低频推理之间的算力博弈。真正的技术壁垒在于如何利用思维链(CoT)与可供性(Affordance)约束,将大模型的泛化能力有效“落地”为精准且安全的机械臂动作,从而消除模型幻觉带来的物理风险。掌握这些涵盖数据闭环、架构选型与部署约束的核心知识图谱,不仅是精准狙击高薪岗位的关键,更是从一名通用算法工程师转型为具备物理世界洞察力的具身智能专家的必经之路。
核心图谱:具身智能面试的知识边界
具身智能(Embodied AI)岗位的面试,往往让求职者感到困惑:它既不像纯粹的大模型算法岗那样只考 Transformer 和 CUDA,也不完全等同于传统的机器人控制岗。为了在面试中精准定位,你需要首先建立清晰的知识坐标系。
核心定义速查表 (Cheat Sheet)
在面试官眼中,具身智能并非简单的“机器人加聊天机器人”,而是一个严谨的系统工程公式。你可以用以下逻辑来界定你的技术栈:
Embodied AI = Agent (Brain) + Body (Hardware) + Environment (Interaction)
- Agent (Brain): 负责感知理解、任务规划与决策(如 LLM, VLM, VLA)。
- Body (Hardware): 执行机构与传感器,负责将数字信号转化为物理动作(如灵巧手、移动底盘)。
- Environment: 物理世界的反馈回路,核心难点在于不可预测性与 Sim-to-Real(仿真到现实)的鸿沟。
面试考察的四大核心象限
大多数具身智能的技术面试题,都会落在以下四个维度的交叉点上:
- 模型架构 (Model Architecture):
- 核心考点: 到底是采用分层架构(Pipeline),即“感知-规划-控制”分离,还是采用端到端架构(End-to-End),即 Vision-Language-Action (VLA) 模型?
- 必备知识: 理解 RT-2、OpenVLA 等模型 如何将图像和语言直接映射为 Action Token,以及传统模块化方案中 LLM 如何作为 Planner 存在。
- 数据策略 (Data Strategy):
- 核心考点: 数据是具身智能目前最大的瓶颈。面试官极大概率会问:“如何解决真实数据稀缺的问题?”
- 必备知识: 熟悉 Sim-to-Real(仿真到真机)的迁移技术、模仿学习(Imitation Learning)与强化学习的数据效率差异,以及如何利用合成数据(Synthetic Data)进行训练。
- 感知与规划 (Perception & Planning):
- 核心考点: 机器人不仅要“看见”物体,还要理解物体的“可供性”(Affordance,即物体能被如何操作)。
- 必备知识: 3D 视觉表征(如 NeRF, 3D Gaussian Splatting 在机器人中的应用)、思维链(CoT)在复杂任务拆解中的应用,以及如何防止大模型在物理世界中产生“幻觉”(例如要求机器人在没有手的情况下抓取物体)。
- 部署与约束 (Deployment Constraints):
- 核心考点: 大模型的低频推理(如 10Hz 以下)与机器人控制的高频要求(通常 500Hz 以上)之间的矛盾。
- 必备知识: 边缘计算、模型量化、推理加速,以及如何设计 分层混合架构 来解耦高层决策与底层控制。
对比分析:传统机器人 vs. 具身智能
在回答“为什么我们需要具身智能”这类宏观问题时,避免空谈“AI 是未来”,建议使用下表进行技术维度的精准打击:
维度 | 传统机器人 (Traditional Robotics) | 具身智能 (Embodied AI) |
|---|---|---|
指令输入 | 固定的代码指令或预设轨迹 | Open-vocabulary (开放词汇),理解自然语言模糊指令 |
泛化能力 | 仅限特定场景、特定物体(过拟合) | Zero-shot / Few-shot,适应未见过的物体和环境 |
感知逻辑 | 状态估计、几何计算 | 语义理解,结合常识推理(如“海绵是软的”) |
核心缺陷 | 缺乏灵活性,环境稍微变化即失效 | 推理延迟高,动作执行的精确度与稳定性面临挑战 |
典型算法 | PID 控制, SLAM, 运动学求解 | Transformer, Diffusion Policy, Imitation Learning |
掌握这张图谱,你就掌握了面试的主动权——接下来我们将深入每一个象限,拆解具体的面试题与回答策略。
架构演进:从分层规划到端到端 VLA

在具身智能(Embodied AI)的面试中,系统架构设计往往是面试官抛出的第一个“杀手锏”问题。这不仅仅是对模型知识的考察,更是对候选人工程视野的测试:你是否理解如何将大模型的语义理解能力(Brain)与机器人的运动控制能力(Body)有效结合?
目前的具身智能技术路线主要分为两大流派,这两种架构的选择直接决定了系统的泛化能力、响应速度和训练成本:
- 分层架构(Modular / Pipeline):这是目前落地最快、应用最广的方案。其核心思想是“大脑”与“小脑”分离。大语言模型(LLM)充当高层规划器(Planner),负责理解指令并将其分解为一系列子任务;底层控制器(Controller)或策略网络(Policy)则负责执行具体的动作控制。这种架构类似于人类的“快慢脑”机制——慢脑负责逻辑推理,快脑负责肌肉记忆。
- 端到端 VLA 架构(End-to-End Vision-Language-Action):这是以 Google DeepMind RT-2 为代表的前沿路线。VLA 模型试图通过一个统一的 Transformer 网络,直接将视觉和语言输入映射为底层的机器人动作 Token(Action Tokens)。这种“Pixels-to-Actions”的模式打破了感知与控制的边界,理论上具备更强的语义泛化能力。
面试官通常会通过对比这两者来考察你对技术演进的理解:从早期的 SayCan 范式(LLM + 预定义技能库)演进到如今的 VLA 模型(多模态大模型直接输出控制信号),每一代架构都在试图解决“语义鸿沟”与“实时性”之间的平衡问题。接下来的章节,我们将深入拆解这两种架构的内部机理与面试考点。
LLM as Planner:大模型如何充当“大脑”

在具身智能的模块化(Modular)架构中,大语言模型(LLM)扮演着“大脑”的角色,负责高层语义理解和任务拆解,而底层的“小脑”或执行器则负责具体的运动控制。这种分层架构是目前面试中考察频率极高的技术路线,其核心在于如何将模糊的自然语言指令转化为机器人可执行的确定性动作序列。
核心工作流:从文本到 API 调用
面试官通常会要求你描述一个完整的推理链路。一个典型的 LLM-based Planning 工作流包含以下四个阶段:
- Prompt Engineering(提示词工程):系统将任务指令(如“把桌上的空瓶子扔掉”)与场景描述、机器人能力清单(Skill Library)封装进 System Prompt。
- High-level Planning(高层规划):LLM 利用语义推理能力,将抽象指令拆解为原子任务序列(Sequence of Primitives)。例如:
Find(bottle)->Pick(bottle)->MoveTo(trash_can)->Place(bottle). - Function Calling / API Mapping:文本计划被映射为具体的函数调用或 API 接口。这一步通常结合 代码生成(Code as Policies) 技术,让 LLM 直接输出 Python 代码而非自然语言,以便利用循环、条件判断等逻辑结构处理复杂任务。
- Low-level Control(底层执行):预定义的运动原语(Primitives)或底层策略网络接收参数,驱动电机执行物理动作。
关键技术点:CoT 与 ReAct
在这一架构中,单纯的“问答”模式往往不足以处理长程任务,你需要掌握以下两种增强推理的手段:
- Chain-of-Thought (CoT) in Robotics:
在机器人领域,思维链不仅是逻辑推理,更是时空推理。例如,当指令是“清洗盘子”时,CoT 需要引导模型先推导出“寻找海绵”、“沾取洗洁精”等隐含步骤,而非直接生成“洗盘子”这个无法直接执行的动作。 - ReAct (Reasoning + Acting):
这是面试中的高频考点。ReAct 模式允许模型在生成行动(Act)之前先生成推理轨迹(Reason),并在执行后观察环境反馈。例如,模型推理“我需要拿起杯子”,执行抓取动作,如果视觉反馈显示“抓取失败”,模型会通过 ReAct 循环进行反思(Reflection)并调整策略,如“尝试重新调整抓取角度”。沙丘社区的分析指出,这种动态规划能力是提升 Agent 自主性的关键。
核心挑战:幻觉与物理落地(Grounding)
“LLM as Planner”最大的致命伤是幻觉(Hallucination)——即模型生成了符合语言逻辑但违反物理约束的计划(例如要求机器人在没有梯子的情况下飞起来取高处的物品)。
为了解决这一问题,面试中必须提及 Affordance(可供性) 概念。
- 问题:LLM 只有语义知识,没有物理世界的“常识”(如重力、物体重量、自身臂展限制)。
- 解决方案:引入价值函数(Value Function)或可供性函数作为过滤器。以 Google 的 SayCan 为例,它将 LLM 的输出(“我想做这件事的概率”)与价值函数(“我现在能做这件事的成功率”)相乘。只有当“想做”且“能做”时,动作才会被执行。这种机制通过环境反馈将高层规划“落地”到物理现实中,防止机器人执行危险或不可能的动作。
VLA 模型详解:RT-2 与 PaLM-E 的核心原理
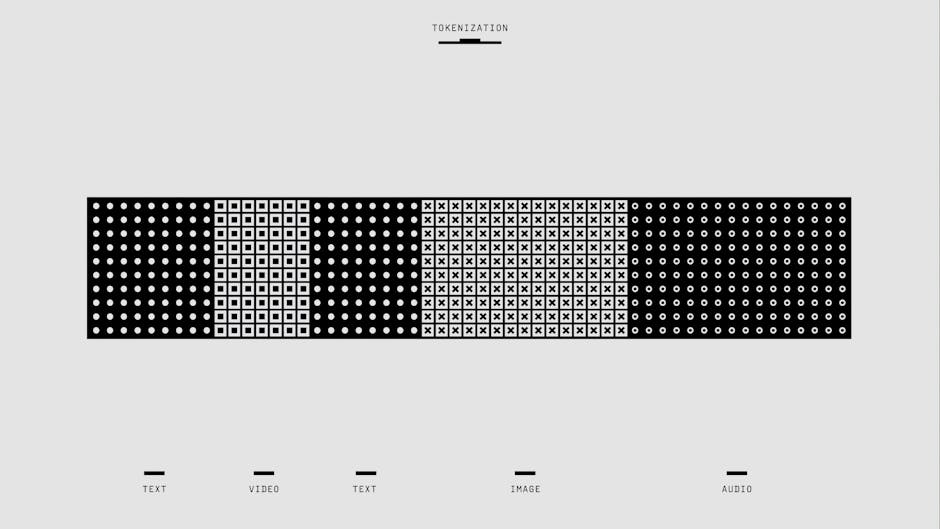
在具身智能的面试中,面试官不仅关注你是否了解大模型,更关注你是否理解大模型如何与物理世界交互。视觉-语言-动作(Vision-Language-Action, VLA)模型是将“大脑”(语义理解)与“小脑”(运动控制)融合的前沿架构。其中,Google DeepMind 的 RT-2 和 PaLM-E 是必须掌握的标杆案例。
1. 核心机制:动作 Token 化 (Action Tokenization)
传统机器人控制依赖连续的数值(如 x=0.25m, y=0.1m),而 LLM 处理的是离散的 Token。面试中被问及“大模型如何直接输出控制指令”时,核心答案在于动作的离散化(Discretization)。
- 词表扩展:VLA 模型将机器人的动作空间映射为文本 Token。例如,将机械臂末端执行器的每一个维度(x, y, z, roll, pitch, yaw, gripper)的值域归一化后,划分为固定的区间(如 256 个 bin)。
- 序列化输出:动作不再是单纯的数值流,而变成了类似单词的序列。
> 技术细节:在 RT-2 中,一个具体的动作指令可能被表示为一系列 Token,例如<actionx128> <actiony055> <actionz200> ... <terminate>。模型像预测下一个单词一样,基于输入的图像和文本指令,自回归地预测这些“动作词”。
正如人民日报关于灵宝机器人的报道中所述,VLA 模型通过融合视觉感知、语言理解与动作控制,打造“端到端”决策系统,“就像一个动作版的大语言模型”。
2. RT-2 的训练策略:互联网数据与机器人数据的协同
RT-2(Robotic Transformer 2)之所以成为面试热点,是因为它成功证明了联合训练(Co-training)的有效性。
- 输入模态:图像(机器人视角)+ 文本(任务指令,如 "pick up the apple")。
- 输出模态:文本回答(用于纯视觉问答任务) 或 动作 Token(用于控制任务)。
- 数据配比:
- 互联网级数据:海量的 Web 文本和图像数据,赋予模型通用的语义理解能力(识别什么是“苹果”,什么是“泰勒·斯威夫特”)。
- 机器人轨迹数据:相对稀缺的真实机器人操作演示数据,教会模型具体的物理控制。
- 面试加分项:你可以指出,RT-2 的关键在于保持了 VLM(视觉语言模型)原有的语义权重,没有因为微调机器人数据而发生“灾难性遗忘”。这使得模型可以将互联网学到的知识“迁移”到物理操作中。
3. PaLM-E 与“具身思维链”
与 RT-2 直接输出底层动作不同,PaLM-E 更多被视为一个具身多模态语言模型。
- 多模态句子:PaLM-E 将连续的传感器数据(如图像、状态向量)编码为向量,直接嵌入到语言模型的输入序列中。输入不仅是文本,而是
Image_Embeddings + "What happened?"。 - 高层规划 vs. 底层控制:在面试中区分两者时,可以说明 PaLM-E 更擅长生成高层的序列规划(High-level Plan),例如“先去厨房,再拿杯子”,通常需要配合底层的控制策略(Low-level Policy)来执行具体动作;而 RT-2 则是端到端的 VLA,直接输出底层的控制信号。
4. 涌现能力 (Emergent Capabilities)
这是最能打动面试官的“各种 Case”。由于 VLA 模型在互联网数据上见过各种概念,它展现出了传统模仿学习不具备的推理能力:
- 语义推理:指令是“把灭绝的动物捡起来”,场景中有恐龙玩具和狮子玩具。传统模型如果没见过这个指令会失效,但 VLA 模型能利用语义知识关联“灭绝”与“恐龙”,并执行抓取。
- 符号理解:指令是“把方块放到写着‘A’的纸上”。模型能理解字符含义并结合空间位置进行操作。
总结回答策略:在回答 VLA 相关问题时,先解释Tokenization如何打通文本与动作的壁垒,再以RT-2为例说明语义知识如何迁移到物理世界,最后用涌现能力的例子证明这种架构的优越性。
数据闭环:Sim-to-Real 迁移与数据稀缺

在具身智能的面试中,面试官最常考察的痛点之一便是“数据饥渴”(Data Starvation)。与大语言模型(LLM)拥有万亿级互联网文本数据不同,机器人领域缺乏高质量、标准化的物理交互数据。如何低成本地获取数据,以及如何利用仿真环境解决数据不足,是区分候选人工程落地能力的关键分水岭。
核心挑战:从“文本海洋”到“物理荒漠”
LLM 的成功建立在海量文本之上,但机器人需要的 (State, Action, Reward) 数据极其稀缺。面试中,你需要明确指出这种差异:
- 采集成本高:真实世界的机器人数据采集依赖遥操作(Teleoperation)或人类演示,时间成本昂贵且具有安全风险。
- 分布不均:大部分现有数据集中在简单的抓取或移动,缺乏复杂长序列任务(Long-horizon tasks)的数据。
必考点:Sim-to-Real(仿真到现实)迁移技术
为了解决数据匮乏,工业界普遍采用“仿真训练,现实部署”的策略。你需要熟练掌握以下核心技术,并能解释它们如何弥合“Reality Gap”(现实差距):
- 域随机化(Domain Randomization)
这是最基础也是最有效的手段。其核心思想是:如果仿真环境的变化足够剧烈,现实世界就仅仅是仿真环境的一个“特例”。
- 视觉随机化:在仿真器(如 Isaac Sim, MuJoCo)中随机改变纹理、光照、摄像机角度和背景噪声,迫使模型学习物体的几何特征而非视觉伪影。
- 动力学随机化(Dynamics Randomization):这是高阶考点。不仅要改变视觉,还要随机化物理参数,如摩擦系数、物体质量、关节阻尼和电机死区。这能极大地提升策略在真实硬件上的鲁棒性。
- 系统辨识与自适应(System ID & Adaptation)
- System Identification:在部署前,通过预定义的动作序列估算真实环境的物理参数,并在仿真中对齐这些参数。
- Online Adaptation:训练一个额外的“适应模块”(Adaptation Module),在推理时根据历史观测数据(History Window)实时调整策略网络,以应对电机老化或负载变化。
模仿学习(IL)与强化学习(RL)的数据效率博弈
面试官常问:“在具身任务中,应该选择模仿学习还是强化学习?” 优秀的回答应结合数据效率和任务特性:
- 模仿学习(Imitation Learning, IL):
- 原理:基于行为克隆(Behavior Cloning),直接拟合专家演示数据(Expert Demonstrations)。
- 优势:训练收敛快,动作像人,适合长序列任务的初始化。
- 劣势:存在分布偏移(Distribution Shift)问题,一旦误差累积,机器人容易进入未见过的状态而失效。且模仿学习难以超越示教者的水平,缺乏探索新解的能力。
- 强化学习(Reinforcement Learning, RL):
- 原理:通过试错(Trial and Error)最大化奖励函数。
- 优势:具备探索能力,能发现比人类更优的策略,且对环境扰动更鲁棒。
- 劣势:样本效率极低(Sample Inefficient),需要数百万次交互,通常必须依赖仿真环境进行训练,再迁移到真机。
高分策略:建议提出“IL + RL”的混合范式——利用模仿学习进行策略预热(Warm-start),解决RL初期探索困难的问题,再利用RL在仿真或真机中进行微调(Fine-tuning),提升鲁棒性和成功率。
进阶话题:合成数据与数据闭环
除了算法,提及数据工程能体现你的实战经验:
- 合成数据(Synthetic Data):利用生成式模型(如基于Diffusion的视频生成)扩充训练数据,生成罕见的边缘案例(Edge Cases),如物体跌落或遮挡场景。
- 数据采集硬件:了解低成本数据采集方案(如使用手机+机械臂组成的遥操作套件)是当前的行业趋势,这降低了从真实世界获取高质量演示数据的门槛。
在回答此类问题时,避免只谈理论公式,多结合具体的仿真器(Isaac Lab, ManiSkill)和迁移失败的排查经验(例如:“模型在仿真中完美,但真机上因为延迟导致震荡,我们通过域随机化延迟参数解决了这个问题”),这将显著增加你的可信度。
工程落地:推理延迟与硬件约束

在具身智能的面试中,面试官不仅关注你对算法原理的理解,更看重你是否具备将大模型部署到真实机器人上的工程直觉。纯软背景的候选人往往容易忽视物理世界的实时性(Real-time)和安全性(Safety)约束,而这正是区分“Paper Reader”与“实战工程师”的分水岭。
频率失配:当 1Hz 的大脑遇到 500Hz 的身体
这是具身智能落地中最经典的工程难题。大语言模型(LLM)或视觉语言动作模型(VLA)通常推理速度较慢,每秒可能仅能输出 1-5 个 Token(1-5Hz);而机器人的底层运动控制(如电机伺服回路)通常需要至少 50Hz 甚至 1kHz 的控制频率才能保证动作的平滑与稳定。
面试官常问: “如果你的 VLA 模型推理一次需要 500 毫秒,但机械臂需要 10 毫秒一次的控制指令,中间的 Gap 怎么填?”
实战解法:分层控制架构(Hierarchical Control)
不要试图让大模型直接驱动电机。成熟的工程方案通常采用“慢思考 + 快执行”的分层架构:
- 上层(Slow Planner): 运行 VLA 或 LLM,负责高层语义理解和任务规划(例如:“去拿起那个红色的杯子”),输出稀疏的航点(Waypoints)或目标姿态。这一层允许有数百毫秒的延迟。
- 下层(Fast Controller): 运行传统的控制算法(如 MPC、PID 或全身控制器 WBC),负责以高频(>500Hz)将上层给出的目标插值为密集的电机指令。
这种架构不仅解决了频率失配,还起到了安全解耦的作用,防止大模型的推理卡顿直接导致机器人“失控”或抖动。
算力与延迟:边缘端部署的残酷现实
在实验室跑 Demo 时,我们常依赖强大的 4090 集群或云端 API,但在工业现场或移动机器人上,往往受限于功耗和散热,只能使用嵌入式 GPU(如 Jetson Orin)或工控机。
优化策略清单:
- 模型量化(Quantization): 将模型从 FP32/FP16 压缩至 INT8 甚至 INT4。根据VLA 模型综述,结合混合精度运算(如 FP16/INT8)的渐进式量化策略,可将计算量减少 2–4 倍,且在保持基准任务性能的同时显著降低内存占用。
- 云边协同(Edge-Cloud Hybrid): 将对延迟不敏感的复杂推理(如长程任务规划、语义理解)放在云端,而将对实时性要求极高的视觉伺服(Visual Servoing)或避障模型部署在边缘端。
- 推理加速框架: 熟练使用 TensorRT 或 ONNX Runtime 对模型进行算子融合与优化,这是工程落地的基本功。
Mini-Case:RT-2 的边缘端优化
假设你在面试中被问到:“RT-2 模型在边缘设备上推理延迟高达 2 秒,如何优化?”
* 分析: RT-2 基于 ViT 和 LLM,参数量巨大。2 秒的延迟对于抓取任务是不可接受的,可能导致目标物体移动后抓空。
* 回答要点: 除了常规的量化,可以提出 “大小模型协同” 方案。使用一个小型的、经过蒸馏的 Policy Network(如基于 ResNet+MLP)在本地高频运行,处理具体的动作执行;只在任务切换或遇到异常(OOD)情况时,异步调用云端或后台的大型 RT-2 模型进行重新规划。
安全约束:如何防止大模型“幻觉”伤人
在纯 NLP 任务中,幻觉(Hallucination)可能只是输出了一句废话;但在机器人领域,幻觉可能意味着机械臂以全速撞向操作员。
必备的工程防线:
- 安全过滤器(Safety Filter): 在大模型输出动作指令后,必须经过一个基于规则或动力学模型的校验层。例如,检查生成的轨迹是否超出关节限位,是否与环境中的已知障碍物(Occupancy Map)发生碰撞。
- 多模态一致性校验: 如果视觉输入显示前方有人,但语言模型生成了“全速前进”的指令,系统应具备安全解耦机制,强制执行急停或降级策略,而不是盲目信任大模型。
- 看门狗机制(Watchdog): 针对网络波动或推理超时,设置硬件级别的看门狗,一旦心跳包丢失,立即锁死电机刹车。
在面试中,主动提及这些“非 AI”的传统机器人学保障机制,能极大地体现你对落地风险的敬畏和工程经验。
高频面试题精选与参考回答 (Model Answers)
在具身智能(Embodied AI)的面试中,面试官不仅关注你对算法原理的记忆,更看重你如何将大模型(LLM/VLM)的通用能力与机器人控制(Control)的具体约束相结合。单纯背诵论文很难通过,你需要展示出对“感知-决策-执行”闭环的深刻理解。
以下是三个最具代表性的高频面试题,建议采用“核心结论 + 技术细节 + 实际考量”的结构进行回答。
Q1: 在你的项目中,是如何解决 Sim-to-Real(仿真到现实)鸿沟的?
考察点:考察候选人是否有落地经验,是否理解仿真器(Simulator)与物理世界动力学差异带来的挑战。
参考回答逻辑(Key Talking Points):
- 定义问题:首先明确 Sim-to-Real 的核心难点在于仿真环境无法完美模拟真实世界的物理摩擦、光照变化及传感器噪声,导致模型在仿真中表现优异(High Success Rate),但在真机上可能完全失效。
- 域随机化(Domain Randomization):
- 视觉层面:在训练时随机化纹理、光照和摄像机角度,迫使模型学习物体本质特征而非环境背景。
- 动力学层面:随机化摩擦系数、物体质量和阻尼参数,训练出鲁棒性更强的策略(Robust Policy)。
- 联合微调与数据混合:
- 引用 Google DeepMind 的研究,单纯使用机器人数据微调往往泛化性不足。更有效的策略是将仿真数据、真机数据与互联网规模的原始网络数据进行联合微调(Co-fine-tuning)。
- 强调真机数据虽然昂贵,但必不可少,通常用于最后的少量微调(Few-shot Finetuning)以对齐物理特性。
- 闭环反馈:提及在推理阶段引入视觉或力控反馈(Visual/Force Feedback),即通过实时观测修正动作,而不仅仅依赖开环的轨迹预测。
Q2: 请解释 RT-1 和 RT-2 的核心区别是什么?为什么 RT-2 被称为 VLA 模型?
考察点:考察对 SOTA 模型架构演进的理解,特别是从“传统 Transformer 策略”到“视觉-语言-动作(VLA)模型”的范式转变。
参考回答逻辑(Key Talking Points):
- 架构本质区别:
- RT-1:本质上是一个基于 Transformer 的动作生成策略(Policy),通常从头训练或基于较小的视觉骨干,主要聚焦于机器人领域的数据,泛化能力受限于机器人数据集的大小。
- RT-2:是一个真正的VLA(Vision-Language-Action)模型。它直接复用了在互联网级数据上预训练的大型视觉-语言模型(如 PaLI-X 或 PaLM-E)作为骨干,将机器人控制任务视为一种特殊的“语言生成”任务。
- 动作 Token 化(Action Tokenization):
- 解释 RT-2 如何输出动作:它将连续的机器人动作(如 6-DoF 位姿)离散化为 Token(例如将动作空间量化为 256 个区间)。
- 关键技术细节:RT-2 扩展了 VLM 的词汇表,新增了专用动作 Token。在训练时,动作 Token 与自然语言 Token 在同一个 Transformer Decoder 中进行自回归预测。这意味着模型可以利用预训练的语义知识(比如认识“超人”公仔)来指导未见过的操作任务,这是 RT-1 难以做到的。
- 推理约束:
- 提到在实际部署时的约束机制:RT-2 在输出动作时,会屏蔽掉非动作的文本 Token,确保输出的是合法的控制指令,从而保证可执行性。
Q3: 你如何评估一个具身智能模型的好坏?只看 Perplexity(困惑度)够吗?
考察点:考察工程思维。大模型背景的候选人容易陷入 NLP 的评估误区,而忽略了机器人任务的物理实效性。
参考回答逻辑(Key Talking Points):
- 否定单一指标:明确指出 Perplexity 或 Loss 只能反映模型对训练数据的拟合程度(预测下一个 Token 的准确率),但在具身场景中,预测准确不代表动作能成功执行。
- 核心业务指标:
- 任务成功率(Success Rate, SR):这是金标准。即机器人是否完成了指令(如“拿起苹果”)。通常需要在真机或高保真仿真器中进行端到端测试。
- 子目标完成率(Sub-goal Completion Rate):对于长程任务(Long-horizon tasks),任务失败可能发生在最后一步。拆解子目标(如:找到物体 -> 抓取物体 -> 移动 -> 放置)有助于定位短板。
- 安全性与效率指标:
- 可执行性(Executability):模型输出的轨迹是否符合运动学约束(Kinematics),是否存在奇异点或碰撞风险。
- 路径效率(Path Length / Efficiency):完成任务的轨迹长度与最优轨迹的比值。一个在原地打转最终才抓起物体的模型,虽然 SR 为 100%,但效率极低,不可上线。
- Sim-vs-Real 相关性:在高级面试中可以提到,评估的一个重点是“仿真评估结果能否预测真机表现”,如果两者相关性低,说明仿真环境构建失败。