
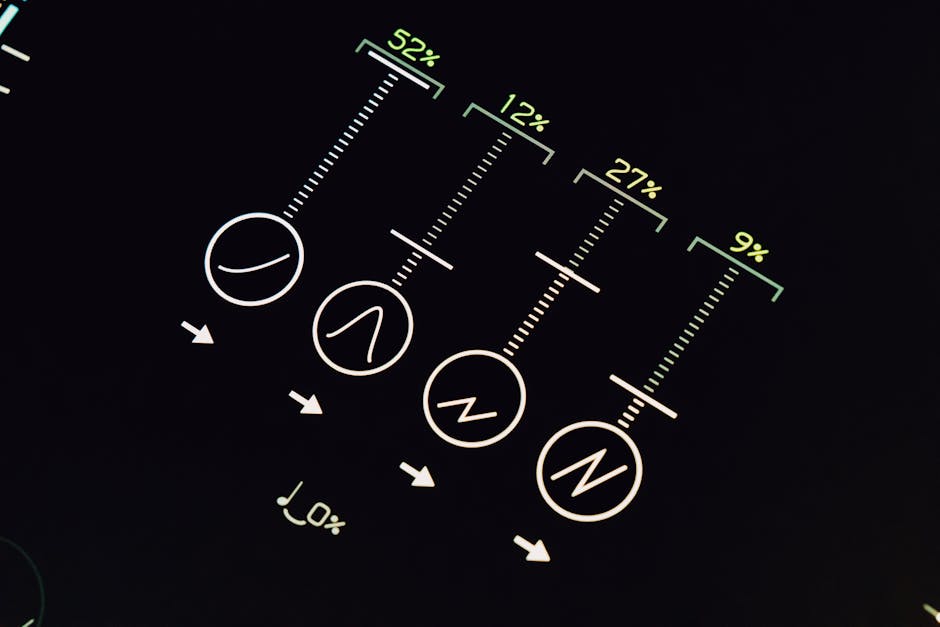
在当前的 AI PM 转型浪潮中,借助大模型进行 PRD 撰写绝非理想化的“一键生成”,而是需要建立一套极度严谨且可落地的 AI PRD 工作流。面对复杂的业务系统,试图用一段冗长的产品经理 AI 提示词让大模型直接吐出完美文档,往往只会触发模型的幻觉与逻辑遗漏。真正的提效之道在于精准界定人机能力边界:利用大模型解决文档冷启动困难、搭建标准骨架并穷举常规异常状态,从而将产品经理从耗时的机械性案头工作中彻底解放出来。无论是在日常工作中使用 ChatGPT 写 PRD,还是在不同模型间进行 Claude PRD 对比以寻找最优解,其底层逻辑都在于摒弃单次生成完整文档的幻想,转而采用包含背景输入、模块拆解、验收标准生成与边缘场景补全的四步递进法则。通过这种结构化的分步对话与精准的 PRD 提示词模板,PM 能够精确控制模型的输出质量,确保一次性生成具备研发可读性的核心功能模块。这种模式不仅直击传统文档格式化耗时的痛点,更在复杂需求 AI PRD 的处理上展现出压倒性优势。它迫使产品经理将节省下来的核心精力,全盘投入到 AI 无法代劳的深水区——处理历史数据兼容、推演跨系统耦合逻辑、制定底层业务规则以及主导跨部门利益权衡。结合真实的 AI PRD 实战案例可以发现,掌握这套方法论并不断利用 AI 迭代 PRD 细节,不仅能将数小时的基础案头工作压缩至十几分钟,更是产品经理在技术演进中重塑核心竞争力、确保业务价值与系统边界绝对可控的必经之路。
核心结论与 AI PRD 标准工作流
对于具备基础产品知识的 PM 而言,借助大模型撰写 PRD 绝非简单的“一键生成”,而是需要通过结构化的分步对话来引导模型输出。经过实战检验,最高效的 AI 辅助 PRD 撰写标准工作流可归纳为以下四个核心步骤:
- 需求输入:向 AI 投喂充分的业务背景、用户痛点与核心目标。
- 结构生成:引导 AI 拆解核心功能模块,建立 PRD 的基础骨架。
- 逻辑填充:分模块细化交互流程、数据流向与验收标准(AC)。
- 边界校验:补充边缘场景,并针对系统限制进行人工审查与修正。
采用这套工作流,能够直击传统 PRD 撰写过程中的核心痛点,实现工作模式的根本性转变:
- 传统撰写模式:面对空白文档常陷入“冷启动”困境;耗费大量时间查阅资料、枚举基础字段;评审时常因遗漏常规异常状态而反复修改。
- AI 辅助模式:利用 AI 瞬间完成基础框架的搭建与常规交互状态的枚举;PM 的核心精力得以释放,只需专注于补充核心业务逻辑与跨部门利益权衡。
避坑指南:在实操前必须明确,AI 的能力存在清晰的边界。大模型擅长搭建标准框架和处理常规交互逻辑,但对于复杂的历史数据兼容性、第三方 API 的调用限制、以及深度的跨系统耦合逻辑,AI 往往会给出过于理想化的方案。这些高风险的业务深水区,依然必须由人类 PM 亲自把控和补充,切忌盲目照搬 AI 生成的业务规则。
接下来,我们将进一步界定 AI 介入的具体场景边界,并详细展开这套四步工作流的实战操作细节。
传统 PRD 撰写的痛点与 AI 介入的边界
很多产品经理在尝试接入大模型时,最关心的问题往往是:“AI 能直接替我写完整份 PRD 吗?”答案是明确的:不能。现阶段的 AI 无法替代产品经理进行复杂的业务决策,但它能完美解决撰写 PRD 时的两大核心痛点——“冷启动困难”与“格式化耗时”。
结合真实的业务场景来看。当你面对一个复杂的后台需求(例如重构涵盖多角色的订单逆向退款链路)时,传统的撰写过程往往伴随着长时间的无从下手。你需要从零开始搭建文档框架、回忆各种异常状态、反复检查是否有遗漏的基础数据字段。而引入 AI 后,它能在几秒钟内为你提供一个结构清晰的基准框架,并自动穷举出常规的异常分支(如并发请求、网络超时、空数据状态),有效解决文档结构混乱和细节描述遗漏的问题。
为了建立合理的预期,我们需要清晰地界定大模型在需求文档撰写中的能力边界。正如在评估AI 时代的产品经理核心能力时所强调的,模型能力是有边界的,清楚哪些任务是现阶段技术实现不了的至关重要。以下是 AI 辅助撰写 PRD 时的明确分工:
模块维度 | AI 擅长做的(提效点) | PM 必须做的(核心价值) |
|---|---|---|
结构与格式 | 输出标准化的文档框架、生成高可读性的排版 | 确定文档的阅读受众(研发、测试或业务方)与沟通侧重点 |
字段与交互 | 罗列表单基础字段、枚举常规交互状态(如加载中、报错提示) | 敲定核心业务字段的底层逻辑、上下游系统的数据流转规则 |
异常与边界 | 穷举通用的边缘场景(如断网、极值输入、并发操作) | 处理复杂的历史数据兼容性、第三方 API 限制与资损风险防控 |
业务与决策 | 基于输入的背景,提炼、总结或润色需求价值 | 制定核心业务规则、进行跨部门利益权衡与 ROI 测算 |
明确了这一边界后,我们就能摒弃“AI 能提升 80% 整体工作效率”这类缺乏实际支撑的口号。真实的效率提升体现在具体的任务拆分上:AI 将原本需要耗费数小时的“搭骨架、写字段、想常规异常”等机械性案头工作压缩至十几分钟;而省下的时间,产品经理必须全盘投入到 AI 无法代劳的系统耦合分析与业务逻辑推演中。这才是务实且不翻车的 AI 辅助工作流。
高效产出的核心四步法则

新手使用大模型撰写 PRD 时,最容易踩的坑就是“试图用一段几千字的提示词,让 AI 直接吐出一份完美的完整文档”。大模型的注意力机制决定了它在处理超长上下文和复杂逻辑嵌套时容易出现幻觉或遗漏。
正确的高效实操策略是分步对话与上下文投喂。通过将撰写过程拆解为四个标准的递进步骤,你可以精确控制 AI 的输出质量,确保最终产物具备研发可读性。
以下是标准操作程序(SOP):
Step 1:需求背景输入(Context & Role Setup)
大模型需要明确的锚点才能生成符合业务语境的内容。这一步不写具体功能,只负责建立明确的角色定位与任务边界,为后续对话奠定基础。
- PM 的输入动作:定义 AI 的专家角色、输入目标用户的特征、当前业务痛点以及核心商业目标。
- Prompt 示例:
> “你现在是一名拥有 10 年经验的高级产品经理。我们的产品是一款面向 B 端商家的 SaaS 订单管理系统,当前的业务目标是降低商家处理退款的客诉率。请仔细阅读并理解这个背景,如果理解请仅回复‘收到,已准备好开始拆解需求’,不需要输出其他内容。” - AI 的预期输出:简短确认收到背景信息,进入待命状态。
Step 2:核心模块拆解(Module Breakdown)
在确立上下文后,输入粗颗粒度的业务需求,利用 AI 强大的归纳能力,将其转化为结构化的功能清单。
- PM 的输入动作:提供一句话需求或初版草图逻辑,要求 AI 遵循 MECE(相互独立、完全穷尽)原则进行模块化拆解,并定义初步优先级。
- Prompt 示例:
> “现在请根据上述业务背景,将‘支持商家批量处理仅退款和退货退款单据’这一需求,拆解为完整的核心功能模块清单。要求以 Markdown 表格形式输出,包含:模块名称、功能子项、核心解决的问题、建议优先级(P0/P1/P2)。” - AI 的预期输出:输出一张结构清晰的表格(如拆分出“筛选与视图模块”、“批量操作模块”、“风控拦截模块”等),帮助 PM 快速核对是否有遗漏的业务骨架。
Step 3:验收标准(AC)生成(Acceptance Criteria)
这是传统 PRD 撰写中最耗时的部分。选定 Step 2 中的某一个核心模块,让 AI 填充具体的业务规则和交互逻辑。
- PM 的输入动作:聚焦单一模块,要求 AI 按照研发熟悉的标准格式(如行为驱动开发 BDD 格式)输出详细的验收标准。
- Prompt 示例:
> “针对上述输出的‘批量操作模块’,请撰写详细的验收标准(AC)。请采用‘Given-When-Then’(假设-当-那么)的结构描述业务规则,并补充正常流程下的前端交互说明(如二次确认弹窗、进度条展示等)。” - AI 的预期输出:高度格式化的用例描述。例如:“假设商家勾选了超过 50 个退款单,当点击批量同意时,那么系统需弹出二次确认框,并在后台异步执行,前端展示处理进度条。”
Step 4:边缘场景补全(Edge Cases & Exceptions)
常规逻辑建立后,必须利用大模型的发散能力来查漏补缺。复杂的历史兼容性和系统限制仍需 PM 最终把关,但 AI 可以极大地减少“未定义的异常状态”。
- PM 的输入动作:转换 AI 的视角,让其以测试工程师或架构师的身份,对刚才生成的 AC 进行极限施压,寻找漏洞。
- Prompt 示例:
> “请切换为一名严苛的测试工程师角色。针对刚才生成的‘批量操作模块’,穷举在弱网环境、并发操作(如多个客服同时处理同一批单据)、部分接口超时、以及极端数据输入(如单次勾选 10000 条)时的异常场景,并给出对应的产品层兜底处理策略。” - AI 的预期输出:一份异常状态枚举清单及处理建议(如“并发操作:建议引入乐观锁机制,前端提示‘部分单据已被其他客服处理’”),PM 可直接将这些策略补充进 PRD 的“全局规则”或“异常流”章节中。
拒绝废话:可直接复制的 PRD 主提示词模板
大语言模型(LLM)本质上是基于概率的文本生成引擎。要让它一次性输出符合研发交付标准的 PRD,关键不在于堆砌华丽的辞藻,而在于为其设定严格的边界条件。
抛开冗长的提示词工程(Prompt Engineering)理论,经过大量真实业务场景的测试与 Token 消耗,我们发现最稳定、容错率最高的 PRD 提示词骨架始终是:角色设定 + 功能模块 + 验收标准。
- 角色设定(Role):直接锚定模型的专业视角(例如“资深 B 端 SaaS 产品经理”),激活其底层对应的专业词汇库与思维模型,使其输出符合行业规范的语境。
- 功能模块(Task & Context):划定需求边界,强制 AI 按照“业务背景-用户故事-交互流程”的标准结构进行输出,避免生成毫无逻辑的发散性长文。
- 验收标准(Quality & Format):这是防范 AI “幻觉”与生成“正确废话”的核心。通过强制要求输出量化指标(如性能约束、并发要求)与异常处理流程(Unhappy Path),迫使 AI 深入思考技术实现的边缘场景。
在接下来的两节中,我们将分别提供一套通用的核心提示词框架(Master Prompt),以及一套应对复杂多系统交互的进阶设定。
使用说明:
下文提供的模板属于“开箱即用”的执行层指令。使用时,你只需将提示词中带有括号的变量占位符(如 [目标用户]、[核心业务目标]、[第三方接口限制])替换为你当前项目的真实业务上下文。无需对 AI 进行任何多余的寒暄,直接复制、替换变量并发送,即可获取结构化的核心模块草案。
万能结构化提示词框架(Master Prompt)
抛弃“帮我写个XX功能的产品需求”这类毫无约束力的指令。真正能让大语言模型(LLM)一次性输出可用核心模块的,是基于第一性原理构建的结构化框架。
以下是一套经过实战检验的 Master Prompt 模板。你可以直接复制,并根据实际需求替换方括号 [...] 中的变量占位符。
# Role: 资深产品经理 & 业务架构师
# Context
我们正在开发 [产品/模块名称] 的最新迭代。
核心业务目标是:[填写核心业务目标,如:将新用户注册到首次下单的转化率提升15%]。
目标用户画像:[填写目标用户,如:缺乏财务专业知识的B端中小企业店长]。
# Task
请基于以下核心功能点,撰写一份极度严谨的 PRD 核心模块文档。
核心功能点:
1. [功能点1简述,如:支持通过微信一键授权登录及手机号绑定]
2. [功能点2简述,如:新用户首次登录后强制引导进入新手配置向导]
# Constraints & Rules
1. 业务逻辑约束:必须考虑 [现有系统限制/第三方接口限制,如:微信OAuth2.0接口的频次限制及Token过期机制] 的影响,不可天马行空。
2. 异常流程(Unhappy Path):必须穷举所有关键异常场景(如:网络断开、并发冲突、权限越权、接口超时、第三方服务宕机),并提供对应的产品兜底策略和全局提示语。
3. 非功能性需求:明确性能要求(如:核心接口响应时间≤500ms,页面渲染≤2s)和多端兼容性要求。
4. 数据埋点需求:列出衡量该功能成功的核心指标,并定义关键埋点事件(Event)、触发时机及所需透传的关键参数。
# Output Format
严格使用 Markdown 格式输出,必须包含以下层级结构:
- 需求背景与用户故事(使用 As a... I want... So that... 格式)
- 核心业务流程图(使用 Mermaid 语法输出 flowchart LR 代码)
- 功能详细说明(必须使用表格呈现:包含 字段/操作名称、交互规则、前置条件、后置状态)
- 异常与兜底规范(详细列出Unhappy Path的处理逻辑)
- 非功能需求与埋点方案
- 验收标准(Acceptance Criteria)(必须是可量化的标准)
⚠️ 严格禁止:不要向我解释什么是PRD,不要输出任何寒暄废话或“好的,我将为您撰写”等过渡句,直接输出最终的结构化文档。框架解析:为什么这个提示词能输出专家级 PRD?
这套模板的核心在于将产品经理的严密逻辑“编译”为了机器指令,有效规避了 AI 常见的“幻觉”和“假大空”问题:
- 前置背景约束(Context):明确
[目标用户]和[核心业务目标]是为了收敛 LLM 的发散范围。AI 极易为了丰富度而堆砌功能,明确业务目标能强制其在生成细节时始终围绕核心价值点进行收敛。 - 强制接管异常流程(Unhappy Path):初级 PRD 往往只关注理想状态下的主流程(Happy Path),而资深设计的价值在于防范风险。通过指令强制要求模型思考并发冲突、接口超时等边缘场景,直接决定了这份 PRD 能否扛住技术团队的架构评审。
- 非功能与数据埋点前置:要求明确性能指标和埋点参数,确保了验收标准的量化(例如量化到“页面加载时间≤2s”而非模糊的“加载速度快”)。这不仅是对研发的明确约束,也为后续的数据复盘提前打好地基。
- 高密度格式锁定(Output Format):通过指定 Markdown 表格和 Mermaid 流程图代码,彻底消除大模型喜欢用大段自然语言描述复杂逻辑的弊端,使输出结果具备极高的可读性,并且可以直接无缝迁移到 Confluence、语雀等文档协作平台中。
应对复杂企业级需求的进阶设定

基础的结构化模板虽然能快速产出单点功能的需求框架,但在应对真实的企业级需求时往往会碰壁。当业务涉及跨系统数据交互、复杂的 RBAC(基于角色的访问控制)权限校验或底层状态机流转时,大语言模型极易陷入“过度发散”或仅考虑“理想路径(Happy Path)”的陷阱。此时,向 AI 描述需求的核心不再是“讲业务故事”,而是“设定逻辑边界”。你需要像配置规则引擎一样,通过绝对严密的逻辑断言来约束 AI 的生成范围,明确告知其哪些操作在当前架构下是被严格禁止的。
以“B端 SaaS 系统的多角色审批流”为例。如果仅向 AI 提示“设计一个包含员工、主管、财务的审批功能”,模型通常会输出一个线性的理想流程,完全遗漏越权审批、驳回重提、并发冲突等边缘场景。为了精准约束 AI 的发散,必须在提示词中开辟一个独立的 [业务规则与逻辑约束] 模块,直接输入具体的权限判定与状态流转条件。
你可以直接在提示词中嵌入如下片段:
请在输出功能流程和验收标准时,严格遵循以下业务规则,绝不能自行发明或篡改权限逻辑:
1. 权限互斥:同一审批流实例中,“财务总监”与“超级管理员”角色不可由同一 UID 兼任。
2. 越级规则:仅当审批节点停留超过 48 小时且触发超时告警后,[超级管理员] 才可执行“越级审批”操作,其余任何角色均无此权限。
3. 状态流转限制:单据状态一旦变更为“已打款”,任何角色(包括系统兜底逻辑)均不可发起“撤销”操作,必须强制走“退款补偿”逆向流程。
4. 多系统交互异常处理:若调用外部财务系统 API 失败(如接口超时或返回 50x 错误),审批单状态必须挂起为“同步异常”,触发重试机制并向发起人发送站内信,禁止直接将单据标记为“审批失败”。这种指令直接封死了 AI 随意捏造业务逻辑的空间,强制其在输出异常流程时严格对齐现有的业务底座。
此外,在企业级产品的迭代中,新需求往往需要向下兼容老系统。将现有的数据库表结构、API 文档或旧版 PRD 作为上下文输入给 AI 是确保产出物具备技术可行性的关键步骤。然而,直接将几万字的旧文档或完整的 Swagger 导出会极易触发 Token 超限,或导致模型出现“中间注意力丢失(Lost in the Middle)”现象,从而忽略关键约束。
为了最大化上下文效率,建议采用“降维提取”的技巧来限制字数并提高信息密度:
- 数据库结构注入:剥离无用的系统字段(如
create_time、is_deleted)和索引配置,仅提取核心业务表的 DDL(数据定义语言)及关键字段注释,使用 Markdown 的 SQL 代码块包裹输入。 - API 接口注入:无需提供完整的接口文档,仅需提供核心交互的 JSON Payload 示例及强校验字段的说明。
- 旧版逻辑注入:将冗长的旧版 PRD 转化为精简的伪代码或 Mermaid 语法的状态机流程图文本。
在实际操作中,可以在提示词末尾以特定的结构附加这些上下文:“以下为当前系统的核心技术上下文,请确保你生成的字段设计与现有表结构完全兼容:\n `sql \n [精简后的 CREATE TABLE 语句] \n ` ”。通过这种高密度的信息投喂,既能将 Token 消耗控制在安全水位,又能让 AI 生成的 PRD 深度契合现有的技术架构,减少研发评审时的阻力。
实战对比:ChatGPT vs Claude 在 PRD 撰写中的表现
撰写一份极度严谨的 PRD 绝非简单的“文本生成”,它要求大模型在错综复杂的业务规则下保持准确的逻辑推理,在长篇幅的输出中维持上下文连贯性,并严格遵循结构化的排版规范。当前,产品经理(PM)日常工作中最常使用的两大核心生产力工具无疑是 ChatGPT(基于 GPT-4 模型)与 Claude(特别是近期在逻辑推演与自然表达上表现亮眼的 Claude 3.5 Sonnet)。
抛开晦涩的技术参数与模型跑分不谈,本节我们将纯粹从 PM 实际撰写需求文档的“真实体感”出发,对这两款顶尖大模型进行客观的横向评测。接下来的内容将重点围绕以下几个核心维度展开:
- 逻辑推理与业务理解:面对多分支的业务流和异常流,谁能更精准地捕捉边界条件?
- 长文本连贯性与上下文记忆:在经历多轮对话和补充参考资料后,谁能更好地克服遗忘、减少内容幻觉?
- 格式遵循与排版美观度:谁能一次性输出结构严谨、无需大量二次排版的标准 Markdown 文档?
为了直观呈现上述差异,我们不仅会对比两者的能力偏好,还将直接引入一段真实的微型需求案例。通过展示大模型直接生成的“原始输出(Raw Output)”与经过 PM 深度审查后的“人工修正版(Final PRD)”对照,精准还原日常工作中的实战复盘过程。
逻辑推理与排版格式能力对比
在真实的 PRD 撰写工作流中,大模型的价值不仅在于“能写字”,更在于能否准确还原复杂的业务流转,并以符合研发阅读习惯的 Markdown 格式输出。经过大量实测,GPT-4 与 Claude(特别是 Claude 3.5 Sonnet)在处理产品需求文档时展现出了截然不同的能力倾向。
为了直观展示两者的差异,我们从产品经理最关心的三个核心维度进行了横向评测:
评测维度 | GPT-4 表现 | Claude 3.5 Sonnet 表现 | 胜出者 |
|---|---|---|---|
复杂业务逻辑推理 | 擅长数据推演、状态机逻辑计算,表现极度严密但略显机械。 | 能精准捕捉业务痛点,文本理解与摘要更具人性化,但在极度复杂的并发推演上偶有遗漏。 | 平局(场景互补) |
Markdown 排版美观度 | 格式中规中矩,常需明确指令(如“请使用表格”)才会调整版式。 | 极具结构美感,自发使用嵌套列表、对比表格和引用块,层级分明。 | Claude |
超长上下文记忆 | 窗口限制较严,长篇 PRD 迭代后期易丢失早期设定的前置条件。 | 具备庞大的 Token 容量,读长文极少产生幻觉;配合官方提示词技巧,长文本信息提取率可达 98%。 | Claude |
1. 理解复杂业务逻辑
在处理涉及多端交互(如“用户端-商家端-后台管理”)或底层状态机流转的需求时,GPT-4 的逻辑推演能力依然是标杆。它能像严谨的测试工程师一样,一步步推导出异常场景(Edge Cases)和边界条件。相比之下,Claude 在理解需求背景和业务目标时表现得更“聪明”,它生成的描述更贴近人类 PM 的自然表达,阅读体验极佳;但在处理纯粹的数值计算规则或极其复杂的数据底层映射时,仍需 PM 介入进行更为仔细的审查。
2. Markdown 排版美观度
一份优秀的 PRD 必须具备极高的可读性,以降低产研沟通成本。在这一点上,Claude 展现出了压倒性的优势。即使在提示词中不加任何排版限制,Claude 也能自动输出结构严谨的 Markdown 文档——它会自发地将接口字段整理成表格,将流程步骤提炼为有序列表,并对关键风险点进行加粗高亮。而 GPT-4 输出的文本往往较为扁平,容易出现大段堆砌的文字,增加了研发的阅读负担。
3. 上下文记忆与长文本处理
撰写长篇 PRD 往往需要跨越多个模块进行频繁的对话迭代,这就极其考验模型的上下文窗口。Claude 凭借其巨大的 Token 容量,在吞吐长篇竞品分析报告或复杂历史迭代文档时游刃有余。不过,实测发现大模型在极长的对话中均会偶发“注意力偏移”(遗忘中间段落的约束条件),但通过结构化的 Prompt 引导,Claude 的长文本信息召回率修复效果极为显著。GPT-4 在短篇幅内的指令遵循度极高,但一旦对话轮次过多、文档超长,极易出现“顾此失彼”的现象。
结论与实战建议:
避免陷入“端水大师”的误区,在实际工作中,组合使用才是最高效的解法。
- 首选 Claude 负责“起建框架与长文输出”:当你需要从零撰写一份结构严谨、排版精美的长篇 PRD,或者需要让 AI 归纳大量历史文档和竞品资料时,Claude 是毫无疑问的首选工具。
- 切换 GPT-4 负责“核心逻辑攻坚”:在处理涉及复杂订单结算逻辑、并发状态推演或数据权限隔离的特定子模块时,建议将 Claude 生成的初步方案喂给 GPT-4,利用其强大的逻辑推理能力查漏补缺,生成极度严密的验收标准(Acceptance Criteria)。
真实案例:AI 原始输出与人工修正对照(Raw vs Final)

为了直观展示大模型在 PRD 撰写中的局限性以及人类 PM 的核心价值,我们设定一个具体的微型需求场景:“电商 App 购物车降价提醒功能”。
在未经过极其严密的 Prompt 约束与上下文喂养时,大模型往往只能生成“看似完整,实则无法落地”的骨架。即便模型具备强大的文本生成能力,在处理复杂业务逻辑时依然存在严重的“逻辑幻觉”。以下是真实测试中的原始输出与人工修正的逐字对比:
业务模块 | 🔴 AI 原始输出 (Raw Output) | 🟢 人工修正后最终文档 (Final PRD) |
|---|---|---|
触发机制 | 当购物车内的商品价格发生下降时,系统自动发送 Push 通知用户。 | 1. 阈值判断:较用户加购时的历史快照价格,降幅绝对值 ≥ 5元,或降幅比例 ≥ 5% 才触发。<br>2. 防打扰策略:同一用户单日最高接收 1 条降价 Push;同一商品 7 天内不重复触发。 |
异常状态 | (AI 完全遗漏此模块,默认所有降价商品均可正常购买) | 防御性逻辑:若商品触发降价,但当前状态为“已下架”或“库存为 0”,则强制拦截通知,并在购物车失效商品区展示降价标签,置灰购买按钮。 |
接口依赖 | 调用 | 禁止前端直连。需通过后端 |
埋点与数据 | 统计点击率和转化率。 | 新增埋点: |
核心修正点严厉剖析
通过上述对比可以发现,直接将 AI 生成的内容扔给研发,注定会引发灾难性的线上事故或返工。人类 PM 的修正过程,实质上是对业务深度的兜底:
- 补全“Happy Path”之外的异常分支
AI 的思考路径具有强烈的“顺向性”,它默认所有降价商品都能顺利购买。人类 PM 必须补全“商品降价但同时缺货/下架”的经典电商 Edge Case。如果按 AI 的原始输出开发,会导致用户收到 Push 满怀期待地点进去,却发现商品无法购买,从而引发严重的客诉与信任危机。 - 引入量化指标与防打扰边界
AI 的逻辑往往是二元对立的(降价 vs 未降价),缺乏对真实商业环境的体感。人类 PM 必须介入定义“业务阈值”(降幅 ≥ 5元)和“频控策略”(单日最多 1 条)。在日活千万级的应用中,如果不加频控直接全量 Push,不仅会瞬间击穿消息推送网关,还会导致极高的用户卸载率。 - 剔除“幻觉接口”,对齐真实架构
大模型习惯性编造一个万能的、开箱即用的接口(如上文的PriceDropNotifyAPI)。在实际企业级微服务架构中,这种高度耦合的接口根本不存在。PM 必须将其拆解,明确上下游系统的真实调用关系(如依赖现有的购物车读取服务与消息推送中台),这要求 PM 对公司现有的系统边界和历史包袱有深刻的认知。
AI 迭代与修改:如何维护和更新已有 PRD

在真实的业务演进中,PRD 极少是一次性定稿的。当需求在中途发生变更,或者进入二期迭代时,产品经理面临的核心挑战不再是“从零生成框架”,而是“如何在不破坏原有逻辑结构的前提下,让 AI 精准完成局部修改”。如果仅凭一句“请根据新需求更新这份文档”来指使大模型,往往会导致上下文丢失、历史业务约束被覆盖,甚至引发全局格式的崩塌。在已有文档的二次编辑场景中,必须将 AI 的角色从“内容生成器”转变为“带有版本控制思维的审查员”,通过明确圈定新功能的“影响面(Blast Radius)”并锁定无关模块,来确保文档的严谨性与连贯性。
要安全地驾驭 AI 进行局部重构,我们需要引入更具防御性的提示词工程(Prompt Engineering)策略。接下来的内容将深入探讨两种进阶手法:首先,我们将演示如何利用苏格拉底提问法,让 AI 扮演挑剔的后端架构师或测试工程师,对变更后的 PRD 逻辑闭环进行深度“找茬”;其次,针对大模型在修补旧系统时极易产生的“幻觉”(如凭空捏造底层数据接口或无视历史版本兼容性),我们将提供一套高标准的人工校验清单,确保 AI 输出的更新方案不仅逻辑自洽,且在真实的工程环境中绝对安全可用。
局部重构的苏格拉底提问法
在维护和更新现有 PRD 时,直接让大模型“修改文档”往往会破坏原有结构,甚至引发前后文的逻辑冲突。更高效的进阶策略是结合反问法与人设法(即苏格拉底提问法),通过角色反转让 AI 扮演挑剔的开发或测试工程师,向产品经理提出针对性的质疑。这种防御性思维的核心在于:不让 AI 直接生成最终方案,而是让它充当“找茬”的外脑,专注挖掘局部重构时引入的新漏洞和边界死角。
具体的实操方法是构建一段强约束的审查提示词。你可以将需要重构的局部 PRD 模块喂给大模型,并附上如下指令:
PRD 漏洞审查提示词模板:
“请扮演拥有 10 年经验的高级后端工程师和苛刻的 QA 专家。请仔细阅读以下 PRD 局部更新模块,专注于寻找逻辑闭环缺失、异常流(Exception Flows)未定义或与历史版本可能产生冲突的地方。请不要直接重写文档,而是向我提出至少 3 个尖锐、具体的边界问题(例如:并发操作时的状态覆盖、极端异常下的降级策略、第三方接口超时处理)。请以提问的形式输出,并等待我的解答。”
这种审查机制本质上是在模拟真实的研发需求评审会(Review Meeting)。在实际应用中,PRD 极易在异常路径上出现疏漏(例如常规文档很少定义“传感器故障”或“缓存击穿”时的具体表现),而 AI 能够基于庞大的工程语料库,精准指出隐性约束。通过在内部评审前引入这一轮“预演”,PM 可以提前修补状态机异常、跨模块依赖等深层逻辑断层,将局部重构的严谨度提升至可直接开发的交付标准,从而大幅降低在真实评审中被研发团队 Challenge 的概率。
规避 AI “幻觉”与历史版本冲突
大语言模型本质上是基于概率的文本生成引擎,这种特性使其在结构化表达与需求拆解上表现优异,但在处理具体的业务边界时,极易产生致命的“幻觉”。在 PRD 撰写中,AI 最危险的幻觉往往不是逻辑不通,而是编造了团队根本不具备的底层能力。例如,AI 可能会在文档中理所当然地设计一套“多端实时数据同步”方案,却完全不知道你当前系统的数据架构仅支持 T+1 的离线跑批;或者它会默认调用一个公司内部根本不存在的“统一用户权限中心”。如果产品经理对这些内容照单全收,不仅会在评审会上被研发团队彻底推翻,还会严重损耗自身的专业信誉。
为了防止这种“看似完美实则脱离实际”的输出,在将 AI 生成的模块合入最终 PRD 之前,必须执行严格的AI 幻觉人工校验清单(Checklist):
- 校验历史系统与旧版本数据兼容性:AI 倾向于设计“理想化”的全新系统,往往会忽略旧版本用户的平滑过渡。必须人工排查:新业务逻辑是否破坏了现有数据表结构?历史遗留的脏数据如何清洗或兼容?AI 是否将本可以复用的现有接口误判为需要全量新增?
- 校验第三方接口与底层物理限制:AI 无法感知外部环境与硬件的客观限制。如果涉及外部对接,必须核对第三方 API 的调用频率限制(Rate Limit)、数据分页逻辑与鉴权规则。对于涉及硬件或物联网的业务,AI 极易漏掉传感器故障、通信中断、存储满载等底层异常场景,这些隐性的物理约束必须由人工显性补全。
- 校验异常流与极端并发场景:AI 默认的生成逻辑往往是“Happy Path”(理想主流程)。你需要带入极端场景进行审查:当用户手动操作与系统自动任务发生竞态冲突时(例如同时修改同一状态),以谁为准?在面对高并发或面向消费者的核心链路时,AI 是否定义了明确的限流规则、超时重试机制和降级策略?
- 校验跨模块的连锁反应:局部最优不等于全局最优。修改一个订单状态机可能会引发下游财务对账系统或仓储系统的异常。审查时需确保 AI 生成的改动范围没有打破全局业务拓扑的平衡。
在给 AI 当 PM 的过程中,我们会深刻意识到:AI 是一个极其强大的副驾驶(Copilot),它能将数天的文档撰写和技术点拆解工作压缩至几十分钟。然而,文档的输出速度从来不是产品经理的核心壁垒。敏锐的业务体感、对组织技术架构历史包袱的深刻理解,以及跨部门协调隐性资源的能力,才是真正决定一个核心模块能否成功落地的关键。AI 负责将意图翻译为严谨的结构化文档,而产品经理,永远要负责为这些逻辑注入真实的商业洞察与技术边界。





